以前にAWS Summitで似た様な話をしているので、こちらのブログとかも参考にしてください。
https://dev.classmethod.jp/articles/aws-summit-online-2020-cus-47/
今回の内容も、公式のドキュメントを全部読むなら大体書いてあることなので、既にある程度知っているという方は、後半の「StateStoreの実態」以降の部分だけを読んでもらえれば特に注意すべきことが書いてあります。
参考
https://docs.confluent.io/ja-jp/platform/6.2.0/streams/index.html
https://docs.confluent.io/platform/7.0.1/streams/index.html
ストリームプロセッシングとは
イベントストリームに対して、データが到着するたびに処理を行い、それが延々と続いていく様なアプリケーションを指します。
Kafkaのエコシステムにおいては、Kafka BrokerにConsumerとして接続して、無限ループでpollingを行い、データが到達する度に短いインターバルで処理を行うアプリケーションのことです。
複数のレコードを使って集計処理を行うケースもあるが、ある一定期間ごとに集計ウインドウを区切った上で、一件ごとに集計結果をアップデートするか、バッファリングしておいて一定のインターバルをおいて実行する処理で集計を行う、といった形を取る。
ステートレスかステートフルか
ストリームプロセッシングの処理内容は大きくステートレスかステートフルかに分けられます。
ステートレスな処理とは、あるイベントレコードが到着した時に、そのレコードだけで処理が完結する処理のことです。
レコードAをレコードBの形に変換して別のトピックや別のデータストアに転送する処理などがその典型です。
一方、ステートフルな処理とは、到達したイベントレコードやそれを基に生成したデータを一定期間保持しておいて、それと組み合わせて結果を生成する処理のことです。
典型的なものでは、イベントの数を集計して合計や平均やヒストグラムを算出したり、処理効率のためにバッファリングしてまとめて処理したり、別のストリームやデータストアとデータを結合してデータエンリッチメントを行うといったものが挙げられます。
ステートフルな処理においては、一定量のレコードを格納しておくデータストアが別途必要になります。それをStateStoreと呼びます。ストリームプロセッシングにおけるStateStoreには重要な考慮ポイントがいくつか存在しますが、それについては後述します。
ステートフルアプリケーションにおけるデータストア
ストリームプロセッシングは、あるデータが到達したらその都度処理が行われるため、何らかのデータストアを利用すると、データが来る度にデータの取得や保存を行うことになる。
そのため重要な要素として低レイテンシであることが求められます。データ量によってはRedisの様なシンプルで高速なKVSであってもネットワークレイテンシが馬鹿にならないため、十分とは言えない場合があります。
そこでストリームプロセッシングでは、基本的に各処理ノードのローカルにデータストアを保持してレイテンシを低く保つという手法を採用します。
後述するKafka StreamsやApache Flinkなどのストリームプロセッシングフレームワークでは、RocksDBが採用されています。
RocksDBはアプリケーションに組込むタイプのKVSで、RocksDBを各ノードのローカルで動かすことで低レイテンシな状態保持を実現します。
各ノードのローカルで動かすということは、ノードが不慮の事故でダウンし復帰不能になった場合データが失われる危険性があることを意味します。
これを避けるためノードに依存しないデータ永続化の仕組みも別途必要です。この仕組みにおいてはネットワーク通信のオーバヘッドは避けられないため、ある程度のバッファリングが必要になります。
また、Kafkaを利用したストリーミングアプリケーションでは、スケーラビリティを確保するためにアプリケーションを分散して複数ノードで動作させることもよくあります。
そういったケースでは、ノード数の増減に応じて処理するパーティションの割り当てが変わる可能性があります。
第1回で解説した様にKafka Consumerは同一のConsumer Groupでは一つのパーティションを処理できるのは一つのクライアントだけです。台数が増減するとその割り当てが再配置されることになり、処理対象が別ノードに移ることを考慮しなければいけません。
処理が別ノードに移ると、それまでに各ノードのローカルで保持していたデータをどうにかして新しく処理が割り当てられたノードに移し替えないと、今迄に保持していたStateStoreのデータが利用できなくなります。例えばノードが増えた途端に集計済みのカウントがいきなり0に戻ったりすることになる訳です。
これを回避するために処理ノードの変遷に合わせてStateStoreを再配置する仕組みが必要不可欠です。
Kafka Streamsとは
Kafka StreamsはApache Kafkaの開発プロジェクトで公式に提供されているストリームプロセッシングフレームワークです。Javaで実装されています。
前段で解説した様にステートフルなアプリケーションを実装しようと思うと、その状態管理に結構複雑な仕組みが要求されます。
Kafka Streamsを利用するとフレームワークがこういった複雑さの面倒を見てくれます。またConsumerクライアントのpollingループや別のトピックにレコードを転送するためのProducerクライアントの集約なども面倒を見てくれるため、ステートレスなアプリケーションであっても大幅にコードを削減できます。
基本的にはここで説明することは Confluent社の提供しているドキュメントに概ね書かれていることになります。
少し古いですが日本語のドキュメントもあるので、詳細を知りたい方はそちらを参照して隅々まで読み込むのが良いでしょう。
https://docs.confluent.io/ja-jp/platform/6.2.0/streams/concepts.html
主な特徴
Kafkaの開発で主要な役割を担っているConfluent社のドキュメントによると以下の様な特徴があります。
機能
- アプリケーションに高い拡張性、弾力性、分散性をもたらし、フォールトトレラントを実現
- 「厳密に 1 回」の処理セマンティクスをサポート
- ステートフル処理とステートレス処理
- ウィンドウ、結合、集約を使用したイベント時処理
- ストリームとデータベースの世界を 1 つにする Kafka Streams の対話型クエリ をサポート
- 宣言型で関数型の API と、下位レベルの 命令型の API を選択でき、高い制御性と柔軟性を実現
軽量である
- 導入へのハードルが低い
- 小規模、中規模、大規模、特大規模のいずれの事例にも対応
- ローカル開発環境から大規模な本稼働環境にスムーズに移行
- 処理クラスターが不要
- Kafka 以外の外部依存関係がない
cf. https://docs.confluent.io/ja-jp/platform/6.2.0/streams/introduction.html
この中でも私が最も重要だと思うポイントが、Kafka以外の外部依存関係がない、という点です。こういった分散処理フレームワークの場合、YARNの様なリソースマネージャーやその他のデータストアが必要になるケースもしばしばありますが、Kafka Streamsにはそれが必要ありません。
これは導入のハードルを大きく下げてくれます。
Tutorialコード
Kafka Streamsでアプリケーションを書くには以下の様なコードを書きます。
(公式ドキュメントからの引用を少し改変したものです)
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.kstream.StreamsBuilder;
import org.apache.kafka.streams.processor.Topology;
StreamsBuilder builder = new StreamsBuilder();
builder
.stream(inputTopic, Consumed.with(stringSerde, stringSerde))
.peek((k,v) -> logger.info("Observed event: {}", v))
.mapValues(s -> s.toUpperCase())
.peek((k,v) -> logger.info("Transformed event: {}", v))
.to(outputTopic, Produced.with(stringSerde, stringSerde));
Topology topology = builder.build();
topology.addProcessor(...);
Properties props = ...;
KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
この様にKafka StreamsはDSLを繋げたりProcessor APIと呼ばれる特定のインターフェースに則ったJavaクラスを実装するだけで、Kafkaに接続するConumerやProducerの構築、処理スレッドの立ち上げなどの面倒を見てくれます。
Kafka Streamsのアプリケーションモデル
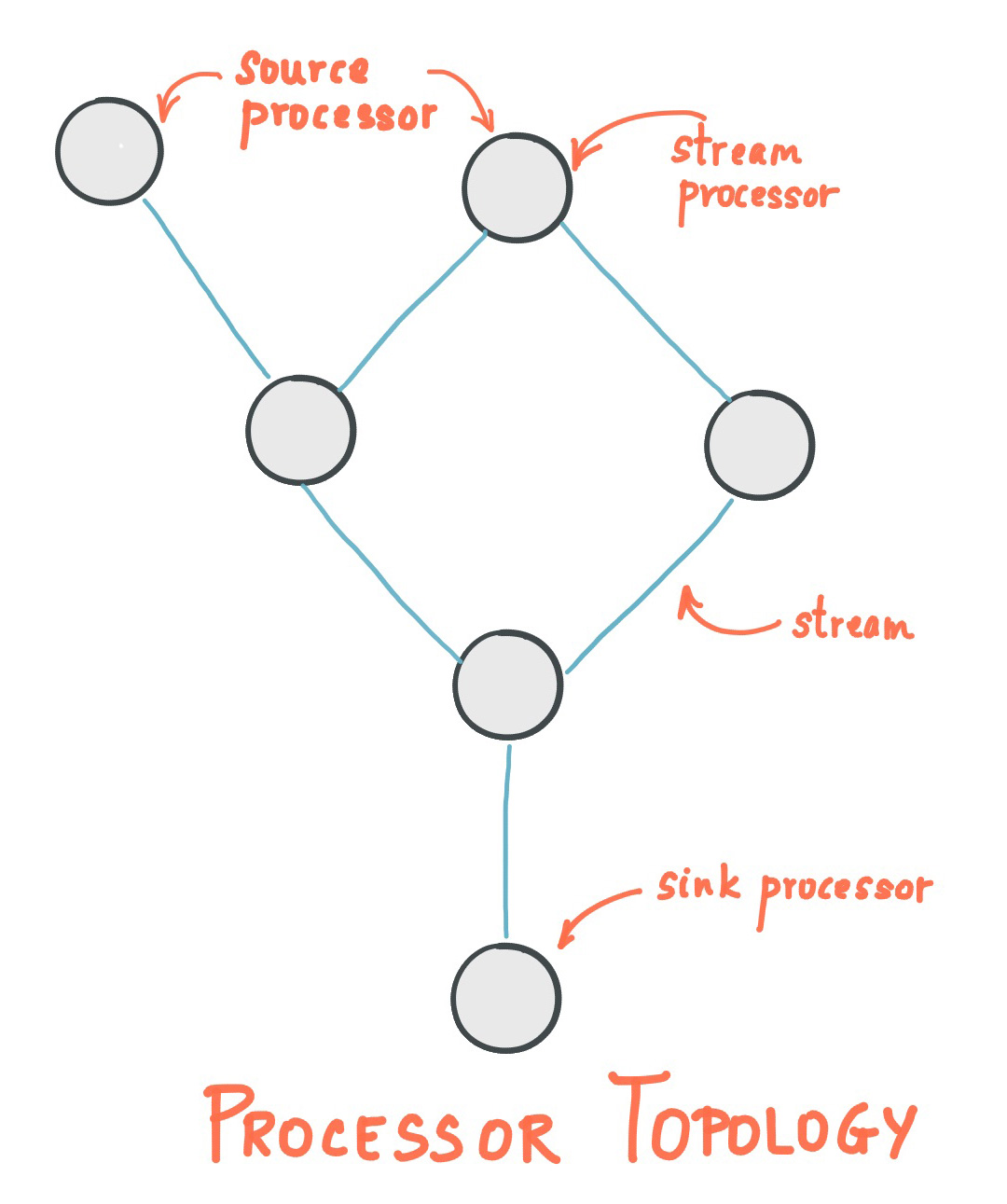
Kafka StreamsはSource Node, Processor Node, Sink Nodeを組み合わせてTopologyという単位を作ることでアプリケーションを構築します。
それぞれどういう意味を持つのか説明していきます。
Topology
Topologyという単語はベースとしては数学用語で位相幾何学を指します。私は数学の徒ではないので詳しくは分かりませんが、物の形状が持つ性質に焦点を当てた学問の様です。
そこから派生してネットワーク・トポロジーというネットワークグラフがどういった構成をしているかの形状パターンを指す用語があります。
Kafka StreamsにおけるTopologyはこのネットワーク・トポロジーと同じものと考えて良いと思います。
Kafka Streamsは特定の役割を持ったノードを接続してグラフ構造を構築しTopologyを形成して動作します。
このTopologyは2つ以上のサブトポロジーによって形成されている場合があります。
 (Confluent Documentationから引用)
(Confluent Documentationから引用)
この様なグラフ構造を1つ以上保持するオブジェクトがKafka StreamsにおけるTopologyです。
2つ以上のサブトポロジーがどうやって生成されるかというと、一つのアプリケーションが複数のソーストピックからデータを取得する様に定義されていて、またそのソーストピックに依存しているProcessor NodeやSink Nodeに直接依存関係が無い場合です。
つまりSource Nodeから辿って一つのグラフが構築される様に依存関係が繋がっている範囲が、一つのサブトポロジーです。
上記の例ではSource Nodeが複数ありますが、下のProcessorが両方のSource Nodeに依存しているためグラフが一つに繋がっているのが分かります。こういった場合はサブトポロジーは1つになります。
もし、左側のSource Nodeがその他の全体と独立してどことも繋がっていないProcessor Nodeにだけ依存している場合は、2つのサブトポロジーが出来ることになります。
Source Node
Kafkaトピックからデータを取得する処理を行うノードをSource Nodeと呼びます。
Kafka Streamsには3種類のデータの取得パターンが存在します詳細はDSLの項で解説します。
上記のサンプルコードのDSLではstreamがそれにあたります。
Source Nodeから受け取ったデータを実際に処理するノードを指します。
実際に開発者が実装するのは、ほぼこのノードになります。
Processor Nodeは複数繋げることが出来ます。処理行程を分割することで見通しの良い実装が可能になります。
上記のサンプルコードのDSLではpeekやmapValuesがそれにあたります。
Sink Node
別のKafkaトピックにデータを送信する処理を行うノードを指します。
上記のサンプルコードのDSLではtoがそれにあたります。
この様にSource Nodeが何らかのトピックからデータを取得し、Processor Nodeで何らかの処理を行いデータを加工したり一時的に保存したり別のデータストアに書き出したりして、そして必要であれば、そのデータを更に別のトピックに書き出して他の処理に繋げていく。
Kafka Streamsのアプリケーションはこうやって構築されます。
Task
Kafka Streamsは当然複数のマシンで分散処理が出来る様にデザインされています。
Kafka Streamsではサブトポロジーがpolling対象としているソーストピックのパーティション数に対応したタスクという単位でクライアントに処理を割り当てます。
例えば、トポロジーAの中にサブトポロジーA-1とサブトポロジーA-2があり、サブトポロジーA-1がトピックB-1をサブトポロジーA-2がトピックB-2を参照しているとします。
この時、トピックB-1のパーティション数が8でトピックB-2のパーティション数が10であった場合、1_0 〜 1_7というタスクと、2_0 〜 2_10というタスクが作成されます。タスクの総数は18です。
この18タスクを現在Consumer Groupに所属しているクライアントに割り当てます。割り当てのストラテジーにはいくつかパターンがありますが、そういった動作の詳細は次回以降で解説します。
上記で解説したTopologyを簡単に構築するために、Kafka Streamsには便利なDSLが用意されています。
DSLを使うことで、Lambdaをメソッドチェーンで繋げる様なインターフェースでストリームアプリケーションを簡単に書くことができます。
これに関しては公式のドキュメントを見る方が明らかに早いので、全体を知りたい方はこちらを参照してください。
日本語版は翻訳が追い付いていないせいか結構古いので最新の機能を知りたい場合は英語版を参照してください。
https://docs.confluent.io/ja-jp/platform/6.2.0/streams/developer-guide/dsl-api.html (ja)
https://docs.confluent.io/platform/7.0.1/streams/developer-guide/dsl-api.html (en)
以降ではこの後の解説に必要な特に重要なDSLについてのみ解説していきます。
KStream, KTable, GlobalKTable
Kafka StreamsのDSLではトピックからデータを取得する方法として3つのパターンを提供しています。
これら3つの入力を表すオブジェクトに対してメソッド呼び出しを繋げることでDSLを記述します。
KStream
単純なKafkaトピックからの入力ストリームを指します。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Long> wordCounts = builder.stream(
"word-counts-input-topic",
Consumed.with(
Serdes.String(),
Serdes.Long()
);
この様に入力を指示する時にSerde(Serializer/Deserializer)を指定します。(実際の入力ではDeserializer側しか利用されないが)
このSerdeを通して、Kafka StreamsはJavaオブジェクトとバイト配列を自動的に変換します。
KTable, GlobalKTable
テーブルの様に扱える入力ストリームを指します。
テーブルの様に扱えるというのは、読み込み始めから現在に至るまでのKafka Brokerに入力された全レコードをローカルに保持していて、他のストリームと結合したりKVSの様に利用できることを意味します。
これは入力レコードの状態を保持しているということでもあり、KTableを使うということはステートフルなアプリケーションである、ということでもあります。
KTableは各パーティションの内容は割り当てられたクライアントにしか保持されませんが、GlobalKTableはあるトピックの全パーティションのデータを全ノードが保持し続けます。そのため入力トピックのデータ量に気を付けて利用する必要があります。
GlobalKTable<String, Long> wordCounts = builder.globalTable(
"word-counts-input-topic",
Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(
"word-counts-global-store" )
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Long())
);
KTableにはストア名とストアするデータのSerdeが必要です。
このストア名で各ノードにはRocksDBのデータベースファイルが作成され、そこにデータが蓄積されます。
このデータストアをStateStoreと呼びます。
上記の例にあるMaterialized.asというメソッドを利用してストア名やSerdeを切り替えたり、その他引数の渡し方でインメモリのデータストアを使う様に変更することも可能です。
StateStoreに保持されたデータは(インメモリストアでない限りは)プロセスが再起動したとしても維持されますが、パーティションの割り当てが変わって担当するタスクが切り替わると不要になったり、新しく再作成が必要になる場合があります。
不要になったRocksDBのデータは一定期間の後に自動的に削除されます。
GroupBy, GroupByKey
KStreamやKTableを集計したい時にどのキーを基にして集計するかを指示するDSLです。countやaggregateの前提として呼び出しておく必要があります。
KGroupedStream<String, String> groupedStream = stream.groupBy(
(key, value) -> value,
Grouped.with(
Serdes.String(),
Serdes.String())
);
groupByを利用すると必ずデータの再パーティションが行われます。再パーティションは、再パーティション用のトピックが自動的に作成され、そのトピック宛にレコードを送信して、再度取得するという処理を行います。
ネットワークやストレージに冗長な負荷がかかるため、再パーティションは極力避けるべきものです。
再パーティション化を避けるためにはgroupByKeyを利用します。
KGroupedStream<String, String> groupedStream = stream.groupByKey(
Grouped.with(
Serdes.String,
Serdes.String())
);
groupByKeyは現在のキーをそのまま使ってグループ化を指示します。この場合は処理の過程でキーが変更されていない限りは再パーティションは行われません。mapなどの変換処理によってキーが変更されている場合はgroupByKeyを使っても再パーティションが実行されてしまいます。
aggregate
DSLの中では最も汎用的な集計処理を実装できるDSLです。
イニシャルの値を生成するイニシャライザ、新しくレコードが届いた時に実行されるアダー、変更前のレコードの情報を利用して実行されるサブトラクター(省略可能)の3つのラムダを渡して集計処理を実装します。
KTable<byte[], Long> aggregatedTable = groupedTable.aggregate(
() -> 0L,
(aggKey, newValue, aggValue) -> aggValue + newValue.length(),
(aggKey, oldValue, aggValue) -> aggValue - oldValue.length(),
Materialized.as("aggregated-table-store")
.withValueSerde(Serdes.Long())
);
集計結果を処理ノードのローカルにずっと維持していなければ、次のレコードが届いた時に今の集計値が何なのかを取得できません。そのため、集計処理は必然的にKTableになります。集計処理した結果はDSLが自動的に構築したStateStoreに格納され保持されます。
StateStoreの実態については色々と解説しなければならない要素があるため、この後でまとめて解説します。とりあえず結果がStateStoreという場所に格納されている、ということを覚えておいてください。
windowedBy
一定の時間ごとに集約範囲を区切ることができるDSLです。この機能を利用することで、5分ごとの合計を算出し続けたり、一回のセッションの中に含まれるイベントの数を数えたりといったことが可能になります。
window処理は時間軸に依存した処理なので、レコードのタイムスタンプと保持期間が重要になります。
場合によっては古いタイムスタンプのレコードが遅れて到着することもあり得ますし、古い集計データをいつまでも保持していたらデータが無限に増えてストレージを圧迫します。
そういった状況に対応するため、window処理には保持期間を別途設定できる様になっています。
KTable<Windowed<String>, Long> timeWindowedAggregatedStream = groupedStream.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.aggregate(
() -> 0L,
(aggKey, newValue, aggValue) -> aggValue + newValue,
Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("time-windowed-aggregated-stream-store")
.withValueSerde(Serdes.Long()));
ウインドウ処理にはその区切り方によって、Tumbling Window, Sliding Window, Hopping Window, Session Windowと現時点で4つの種類があります。
割とややこしいため、 https://docs.confluent.io/ja-jp/platform/6.2.0/streams/developer-guide/dsl-api.html#windowing を参照することをオススメします。
Kafka Streamsのlow level APIにあたるもので、上記のDSLは全てこのProcessor APIで実装されています。
端的に言えば、Processor APIは単なるクラス定義として利用できます。
initメソッドにProcessorContextというオブジェクトが与えられるので、それを利用してKafka Streamsの情報を入手したり、StateStoreへの参照を取得したり、後続の処理にデータを送ったりすることができます。
詳細は、 https://docs.confluent.io/ja-jp/platform/6.2.0/streams/developer-guide/processor-api.html を読んでください。
処理の実態はprocessメソッドに実装する様になっており、レコードが到達する度にこの処理が呼ばれます。
また、一定時間ごとにスケジュール処理を行うこともできます。
ProcessorContextl#scheduleメソッドでPunctuatorと呼ばれる処理を登録することで一定期間ごとに自動的に実行できます。
実行間隔のタイムスタンプをどう扱うかについてKafka StreamsはSTREAM_TIMEとWALL_CLOCK_TIMEの2種類を提供しています。それぞれの違いについては上記リンクに詳細がありますので、そちらを参照してください。
以下は、上記のドキュメント(英語版の最新)から引用したコードサンプルです。
重要な箇所はStateStoreを取得している箇所と、スケジュール処理を登録している箇所、そしてcontext.forwardを呼び出して後続にレコードを渡している部分です。
public class WordCountProcessor implements Processor<String, String, String, String> {
private KeyValueStore<String, Integer> kvStore;
@Override
public void init(final ProcessorContext<String, String> context) {
context.schedule(Duration.ofSeconds(1), PunctuationType.STREAM_TIME, timestamp -> {
try (final KeyValueIterator<String, Integer> iter = kvStore.all()) {
while (iter.hasNext()) {
final KeyValue<String, Integer> entry = iter.next();
context.forward(new Record<>(entry.key, entry.value.toString(), timestamp));
}
}
});
kvStore = context.getStateStore("Counts");
}
@Override
public void process(final Record<String, String> record) {
final String[] words = record.value().toLowerCase(Locale.getDefault()).split("\\W+");
for (final String word : words) {
final Integer oldValue = kvStore.get(word);
if (oldValue == null) {
kvStore.put(word, 1);
} else {
kvStore.put(word, oldValue + 1);
}
}
}
@Override
public void close() {
}
これをKafka Streamsの中に組込むにはTopologyクラスのコンストラクタ、またはStreamBuilder#buildで生成されたtopologyに対してTopology#addProcessorを呼び出すことで、任意のProcessorクラスを差し込むことができます。
また、この時利用したいStateStoreがあればその名前を渡して関連付けておきます。そうでないとProcessor APIからStateStoreを見つけることが出来ません。その場合は例外が発生します。
Topology topology = new Topology();
topology.addSource("Source", "source-topic")
.addProcessor("Process", () -> new WordCountProcessor(), "Source")
.addStateStore(countStoreSupplier, "Process")
.addSink("Sink", "sink-topic", "Process");
StateStoreの実態
公式で提供されているStateStoreは大きく分けてRocksDBを利用したpersistentストアとプロセスが終了すると揮発するインメモリストアの二種類ありますが、一般的によく使われるのはpersistentの方だと思います。まず共通の要素について解説していきます。
ちなみに、APIの形式に則って自分で実装してしまえば、独自のStateStoreを定義することも可能です。
StateStoreをlow level APIで利用する場合は自分でStateStoreを構築することができます。
StoreBuilder countStoreBuilder =
Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("persistent-counts"),
Serdes.String(),
Serdes.Long()
);
これをProcessor APIで利用したい時には以下の様な形で利用します。
KeyValueStore<String, Long> counterStore = context.getStateStore("persistent-counts");
long count = counterStore.fetch("key");
count++;
counterStoreB.put("key", count);
この例では単純なキーの完全一致による取得を行っていますが、Kafka Streamsが提供しているStateStoreはキーのバイト列でソートされているため、rangeメソッドを使って一定の幅のキーを取得することもできます。
StateStoreにおいて重要な要素は以下の通りです。
- KVSであり、キーの順番でソートされている
- キーもバリューも実際に格納される値はバイト列であり、アプリケーションとやり取りする際にはSerialize/Deserializeを行う
- changelogトピックを利用して耐久性を担保する
- 読み書きに関するcacheの仕組みを持っている
先程軽く触れましたが、StateStoreを利用すると自動的にchangelogトピックというものがKafka Broker上に作成されます。(インメモリストアの場合はデフォルト無効)
changelogトピックはStateStoreに書き込まれた変更内容を保持しているトピックです。StateStoreにデータが書き込まれたり削除されたり(nullを書き込む)する度に、changelogトピックにレコードが送信されます。
Kafka Streamsではこのchangelogトピックを使って処理ノードのダウンやタスクの再割り当てに対応します。
新しくKafka Streamsのプロセスが立ち上がった時、もしそのアプリケーションがStateStoreを利用する様に定義されていて、かつそのローカルストレージにStateStoreのデータが存在しない場合、Kafka Streamsはレストア処理を行いKafka Broker上に存在するchangelogトピックから全てのレコードを取得し、ローカルのStateStoreを復元します。
同様にノードの増減によってリバランスが実行され、タスクが再割り当てされた時にも、自身のローカルに割り当てられたタスクIDに対応するStateStoreが存在しなければ、まずレストア処理が走ってから処理が継続されます。
Kafka Brokerはproductionで運用する場合普通であれば3つ以上のレプリカを持つ様に設定されており、データ自体の耐障害性はKafka Brokerの機能によって担保する様になっています。
レストア処理の注意点
StateStoreを活用する上で最も注意しておかなければならないことはレストア処理です。
Kafka Streamsはレストアが必要になった時点で処理を停止します。処理が開始・再開されるのはレストア処理が完了した後です。
つまり、StateStoreに溜まっているデータ量が非常に多くなると、レストア処理にかかる時間も長期化していき、いざノードがダウンしたり増減したりする時に、長時間処理が停止する危険が生じます。
これを避けるのは現状かなり難しい問題です。一定以上古いデータや利用頻度の低いデータはネットワークのオーバーヘッドを許容して外部ストアに逃がすなど、データ量を削減する仕組みをコツコツ積み重ねるしかありません。
StateStoreを作成する時、StoreBuilderのwithLoggingDisabled()を呼び出しておくと、changelogとの対応関係を無効化することができます。インメモリストアの場合はデフォルトで無効になっています。
changelogトピックが無効になっているとレストア処理が実行されません。RocksDBストアを利用している場合、同じノードで同じIDのタスクが実行されている限りはそのデータが保持され続けます。
一方で、Consumerのリバランスによりタスクの再配置が行われた場合や、処理ノードがダウンして復帰不可能になった場合は、そのデータは消滅します。
主な用途はローカルキャッシュです。メモリに乗り切らない量でもファイルシステムを利用してノードローカルなキャッシュとして利用することが出来ます。
例えば、不変のデータであれば外部のデータストアに蓄積しておいて、最初の一回はネットワークアクセスのオーバーヘッドが発生するが、その後はローカルのファイルシステムにキャッシュしてネットワークを経由したアクセスを回避する、といった用途に利用できます。
StateStoreのキャッシュ
ストリーム処理はその性質上短期間に同じキーのデータを何度も読み書きする可能性が高いものです。例えば、あるuser_idのリンクを踏んだ数などをカウントしている場合、そのイベントレコードが集中して何件も届くというのは十分あり得ることです。
こういった時に、都度ストレージにデータを書き込んでchangelogトピックを更新するのは無駄なオーバーヘッドに繋がる場合があります。
Kafka Streamsではそれを避けるためにデフォルトでキャッシュが有効になっています。書き込んだ内容は一定期間メモリ上に保持され、flushタイミングで実際のStateStoreに書き込みchangelogを更新します。
DSLで構築されるKTableではこのキャッシュ機能を利用してforwardが遅延されます。
例えばaggregateで集約された結果を次のDSLで利用したり別のtopicに送信したりする際には、デフォルトの挙動では一定期間StateStore上にキャッシュされてそこでバッファリングされます。一定時間の経過かキャッシュ用のメモリ領域を使い切ったら、CacheFlushListenerがレコードを次のProcessorにforwardします。
WindowStoreの実態
先程DSLの説明の中でwindowByというDSLについて紹介しました。このDSLを利用することで一定の時間ウインドウごとにレコードを集計することが出来ます。
実はこれはWindowStoreというStateStoreのバリエーションによって実装されています。
WindowStoreを作成する時は以下の様にします。1分毎のウインドウ幅で、2時間分のデータを保持するWindowStoreは以下の様に作成します。
StoreBuilder<WindowStore<String, Long>> counterStoreByMinute =
Stores.windowStoreBuilder(
Stores.persistentWindowStore(
"counter",
Duration.ofHours(2),
Duration.ofMinutes(1),
false),
Serdes.String(),
Serdes.Long());
これをProcessor APIで利用したい時には以下の様な形で利用します。
WindowStore<String, Long> counterStoreByMinute = context.getStateStore("counter");
long durationMillis = Duration.ofMinutes(1).toMillis();
long currentWindowStart = (context.timestamp() / durationMillis) * durationMillis;
long count = counterStoreByMinute.fetch("key", windowStart);
count++;
counterStoreByMinute.put("key", count, currentWindowStart);
キーバリューストアにタイムスタンプを合わせて付与する形で取得や保存を行います。
DSLの裏側にある場合は自動でtimestampからTime Windowを設定してくれますが、WindowStoreを直接扱う場合は、TimeWindowの開始となるタイムスタンプがどこかは手動で算出する必要があります。
WindowStoreに事前に与えられたWindow Durationは、記録されたタイムスタンプを基準にしてどれぐらいの長さのウインドウなのかを示す際に使われます。
上記の例は非常にシンプルな形でしたが、timestampの開始と終了時刻を渡すことで、その範囲に含まれるレコードを順番に取得することもできます。
また、通常のKeyValueStoreと同様にキーのレンジ探索とtimestampの開始と終了時刻のレンジ探索を組み合わせることも出来ます。
内部実装としては、WindowStoreは複数のRocksDBのストアから成り立っていて、記録するタイムスタンプごとに大まかなsegmentに分割されています。保存する時にtimestampから対応するsegmentを特定しその領域にデータを書き込みます。
取得する時は対象範囲のsegmentからのみデータを取得することで探索範囲を小さくしています。
またtimestampの範囲でsegmentが決定できるため、現在処理しているタイムスタンプと比較して保持期限を過ぎたものは、まとめてファイルごと削除することで簡単に破棄できます。
書き込み時にはレコードに与えられたキー(上記の例では"key"文字列)の末尾にミリ秒単位のunix timestampが自動的に付与されて記録されます。
次回に続く
非常に長くなったので、一旦ここらで区切って続きはまた次回とさせていただきます。
次回はDSLでは実現できないがProcessor APIでなら実現可能な応用編と、実際にアプリケーションを開発する時の基本的な考え方について解説する予定です。
