コロナが蔓延してから美味しいものを食べるために外食するという行為がほぼ無くなってしまい、お金を稼ぐモチベーションが薄れていたので、いっそ散財してモチベーションを取り戻そうと思い、自宅の環境改善としてオーディオにお金をぶち込んでみた。
ついでにMacを使わなくなってしばらく経つのに、iPhoneとの連携のためにiTunesとfoobar2000を無理やりLinuxで使ってたのを止めようと思いソフトウェア周りも一新することに決めた。
ハードウェア刷新
新しいヘッドホン
基本的に音楽はヘッドホンで聴くのだが、自分はゼンハイザーというメーカーのヘッドホンが昔から好きなので、まずは、そこのフラッグシップモデルであるHD800Sを買う。
実はHD820という後継のモデルもあったのだが、レビューを見る限りでは低音が多少HD800Sより強く出るが、HD800Sを持ってる人が買い替える程じゃないというコメントが多く、値段に10万以上差があったので、HD800Sにしました。
新しいヘッドホンアンプ
そして、HD800Sのために本家が作ったヘッドホンアンプのHDV820も合わせてポチった。ヨドバシで溜まってたポイントを全部費しても27万円もした。
https://www.yodobashi.com/product/100000001003662474/
今迄はゼンハイザーのHD700とDr. DAC2という大分昔に買った4万円ぐらいのヘッドホンアンプだったが、明らかに音の解像度が上がったのでお金出して良かったと思う。
ちゃんとバランス接続するとすげーなこれは。
新しいオーディオI/F
ついでに遥か昔に歌の練習のために持ってたオーディオI/Fがいつの間にかLinuxで動かなくなってたので、そっちも刷新した。
これはLinuxで動くのが確認取れてて1万円ちょっとの代物をサクっと買った。 これにShureのSM58というメジャーで安価なマイクを挿して使っている。
ソフトウェア刷新
Linuxで聴くための環境作り
もう何年間foobar2000を使ってたか分からんし、今もあれが一番使い易くて便利だと思うのだが、LinuxがメインPCになってから流石に32bitのwineをずっと使い続けるのに疲れてきた。 という訳で、最低限以下の要件を満たすプレイヤーを探すことにした。
- Linuxで大量の曲が管理できる (20000曲以上)
- タグを使った検索が簡単で高速である
- DACにリサンプリング無しでデータが転送出来る
- レーティングの移行がし易い
- タグに埋め込み済みの歌詞表示が出来る
1日かけて探して回って、UIに若干の不満があるが一つだけ必要な機能を全て満たすプレイヤーを見つけた。
それがCantataである。

Cantataについて
CantataはMPD (Music Player Daemon)というLinuxを音楽サーバにするためのソフトのクライアントだ。 実際に音楽データのデータベースを管理し再生するのはMPDの方になる。
MPD自体は非常に多機能で歴史も長い。 大体のファイルフォーマットはdecodeできて、ALSAのhwを直接参照してbit perfect (データ変換無し) でDACにデータ転送も出来るし、HTTPサーバーを立ててストリーミングさせたりicecastサーバにデータを流したりできる。
また、DSDというハイレゾ音源でしばしば使われるPCMと異なったサンプリング方式のデータも、PCM変換無しでDACに送ることができる。(完全なDSDネイティブ再生とDSD Over PCMがあるらしい)
今回購入したHDV820はDSDの再生に対応しており、DSD Over PCMを使ったネイティブ再生がLinuxでも動作確認できた。
CantataのUIの不満なところは一覧表示した時に画面に出せる情報が少ないという点と、表示の自由度が全然無いという点。
UIのフォントサイズを調整する設定すら存在せず、マジかよこれだからLinuxは……という気持ちになる。4K解像度でそのまま使うと視力が1.5無いと辛いと思う。QT_SCALE_FACTORで雑に拡大するしかない。
もう一つ気になる点は、既に新機能の開発は終了しており、現在はバグ修正のみがメインとなっているところ。まあ、foobar2000も大差無い様な気がするし必要な完成度はあるのでこの点は気にしないことにした。
ちなみに上述の要件の中で満たすのが難しかったのが、レーティングの移行と歌詞表示である。
変に独自のデータベースを持ってるとレーティングをimportするのが大変だったのだがCantataのレーティングはMPDのstickerという機能を単純に利用しているだけで、MPDのstickerは実際はただのSQLiteデータベースなので元のデータの一覧さえ出せれば簡単に移行が可能だった。
歌詞表示はiTunes & foobar2000時代はLYRICSというタグに歌詞を埋め込んでいたのだが、これを表示してくれるプレーヤーがほぼ存在しない。探した中ではCantataしか無かった。 非常に手間をかけて全部テキストファイルとして抽出しなおせば何とかなったっちゃ何とかなったのだが、面倒は少ない方が良い。
ちなみに調べた中で他に良さそうだったプレイヤーソフトはMPDクライアントだとgmpcで、MPDを使わないプレイヤーだとStrawberryとQuod Libetが良さそうな感じだった。 普通DSDの再生とか気にしなくて良いと思うので、完全に新しく音楽ライブラリを作るならこの辺りでも良さそう。
iPhoneで聴くための環境作り
iTunesに依存しないためには、Appleのクラウドサービスを使わずにiPhoneで音楽を聴く方法が必要だ。
これも色々と探してみたが、現状と同等の環境を得るために使えそうなのはYoutube Music (Google Play Musicは年内終了らしい)とSubsonicの二つが有力だったので試してみた。
Youtube Musicは、無料で10万曲も楽曲を送れるし、flacもそのまま送れてむしろiTunesより良いじゃんという感じではあるのだが、メインがYoutube側なので、自分のアップロードしたライブラリを視聴するのに1タップ要るのがめんどい。 後、アップロード機能が出来たのがごく最近であり、全くツールが無くてめちゃめちゃ不便だ。ブラウザで20000曲もデータ送るの大変過ぎるだろ。 一応、フォルダをD&Dしたら再帰的に読んでくれるのだが、おもむろに2000曲ぐらいまとめてアップロードしてみたら4時間ぐらいかかったし、Chromeのメモリ消費量が16GBぐらいになった。ハングしなかったのは幸運と言える。 アップロードがこなれてきたら、割と使えるとは思う。
Subsonicは自分のPCにサーバを立てて音楽ライブラリに外部からアクセス可能にするソフト。 ライブラリ構築が早いし、プレイヤー側のアプリ次第ではFLACがそのまま再生できるのが良い。
実際のところ自分でサーバー立てるのに何も苦労が無いならSubsonicの方が大分楽だと思う。 問題点は自宅サーバーが落ちたらアウトであるという点と、バックアップ代わりにはならない点か。
現状、Subsonic側が有力な選択肢になっている。
しかし、Youtube MusicもSubsonicもiTunesで埋め込んだ歌詞は見れねえ……。
まあ、実際のところ、そもそも外出とか全然しない世の中になった訳で、外で移動中に音楽聴くとか出来なくても大して困らんっちゃ困らん気もする。今となっては程々で良い
録音環境
インターネット越しにカラオケ会をやるという目標のためには、音楽をPC上で再生しオーディオI/Fで音声を取り込んでリバーブを軽くかけた上でミックスするという工程をリアルタイムで実行したい。
しかし、実際に歌ってみて違和感が無い様にするには結構な低レイテンシが必要であり、Linuxで普通使われるpulseaudioでは大分厳しいものがあった。
pulseaudioでマイク入力取ってエフェクトをかけるとどうやってもローカルで40msecぐらいのレイテンシがある。 更にpulseaudioで音をミックスしてスピーカーに出すところでも数十msecぐらいはレイテンシがある。 自分でヘッドホンで音楽を聴きながらモニタバックした時に数十msecもズレてると歌えたものではない。
なので、低レイテンシなオーディオ環境構築に特化して作られたJACK Audio Connection Kitを使うことにした。
JACKの利用法
pulseaudioが動いてサウンドデバイスを掴んでると使えないので、JACK Audio Connection Kitを使う時はpulseaudio -kでpulseaudioを一旦殺す必要がある。
pulseaudioを殺したら、cadenceというJACKサーバーを管理してくれるフロントエンドがあるので、そいつを起動する。
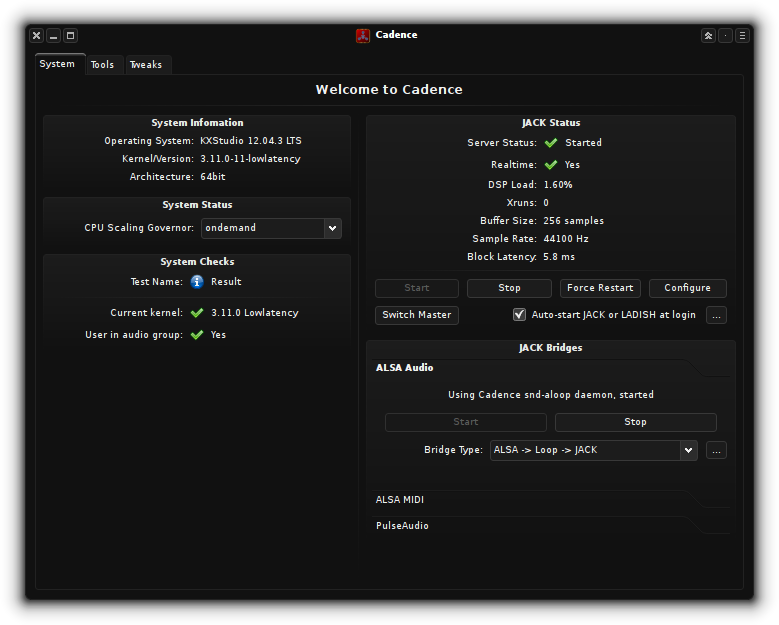
alsaのユーティリティツールであるaplayやarecordを使ってサウンドデバイスのIDを調べてdeviceに指定してJACKを起動したら、使える様になる。 JACKに対応していないアプリケーション (Chrome)とかで音を出すためにはpulseaudioとJACKをブリッジしてくれるプラグインを使う。
PulseAudio/サンプル - ArchWiki が参考になる。
サンプリングレート, buffer size, periodsで大体レイテンシが決まるのだが、自分の環境だとブロックレイテンシを3msecまで下げることが出来た。 いくつかエフェクトを追加しても余裕で10msecぐらいで収まる。
リアルタイムでミックスする時
patch bayというジャンルのソフトを使う。cadenceにはcatiaというpatch bayが付属しているのでこれを使う。
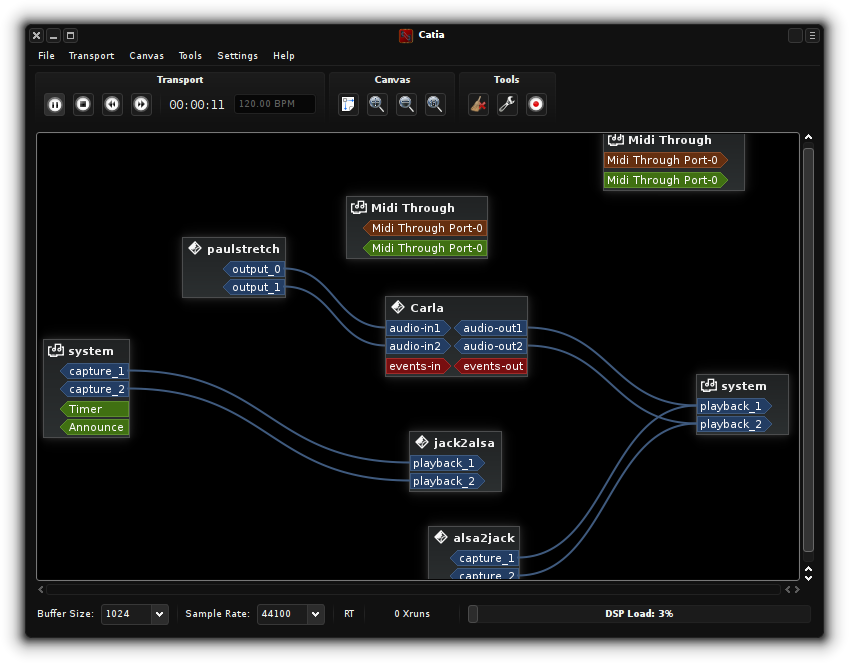
こんな感じで、入力やフィルターや出力をグラフィカルに配線して繋ぐことができる。
これでマイク入力にエフェクトをかけてスピーカーに繋いだりできる。
エフェクトをかけるには色々と手段があるのだがJack-Rackというのが手頃だったので、これを使って軽くリバーブをかけてmixできる様になった。
インターネットカラオケに向けて
JACKに対応したオープンソースのリモートでジャム・セッションをやるためのアプリケーションとして Jamulusというのがある。WindowsやMacにも対応している。
先に紹介したCatiaで色々繋げれば、ニンテンドーSwitchのJOY SOUNDアプリから音を流しつつ自分の声を重ねてJamulusに繋げば、インターネット越しに一緒にカラオケできるんじゃねえのかという可能性を考えている。
ただ問題なのは、まともなスペックのPCと低レイテンシな音声入出力環境 (WindowsだとASIO必須)、そして40msec以下の遅延で通信できる環境が必要になる点だ。
俺の自宅は全て揃っているが、そんなの揃ってる人がカラオケ友達にほぼ居ないので実験が出来ない。DTMやってて、かつ良いインターネット回線持ってる人とか結構少ない……。
という訳で、現状はただの妄想である。
まあ、俺がカラオケで歌っているところを一方的に配信することは出来る様になったw
というわけで、Linuxで結構真面目にオーディオ環境を整えてみた。 あんまりこういう事やる人は居ないと思うが、思い立ってラズパイを音楽サーバーにしたいとか考える人には参考になるかもしれない。
ちなみにお金が劇的に減ったので、金を稼ぐモチベーションは戻ってきたw















